How to Run DeepSeek Inference API Cheaper, Faster, and More Reliably
DeepSeek has emerged as a powerful open-source alternative to proprietary AI models, offering GPT-4-level reasoning at a fraction of the cost. This article sets the stage by addressing a key challenge for developers and teams: how to run DeepSeek inference reliably, affordably, and at scale. It compares various hosting providers and makes the case for a specific platform that prioritizes speed, transparency, and developer-centric features.
Key Ideas
-
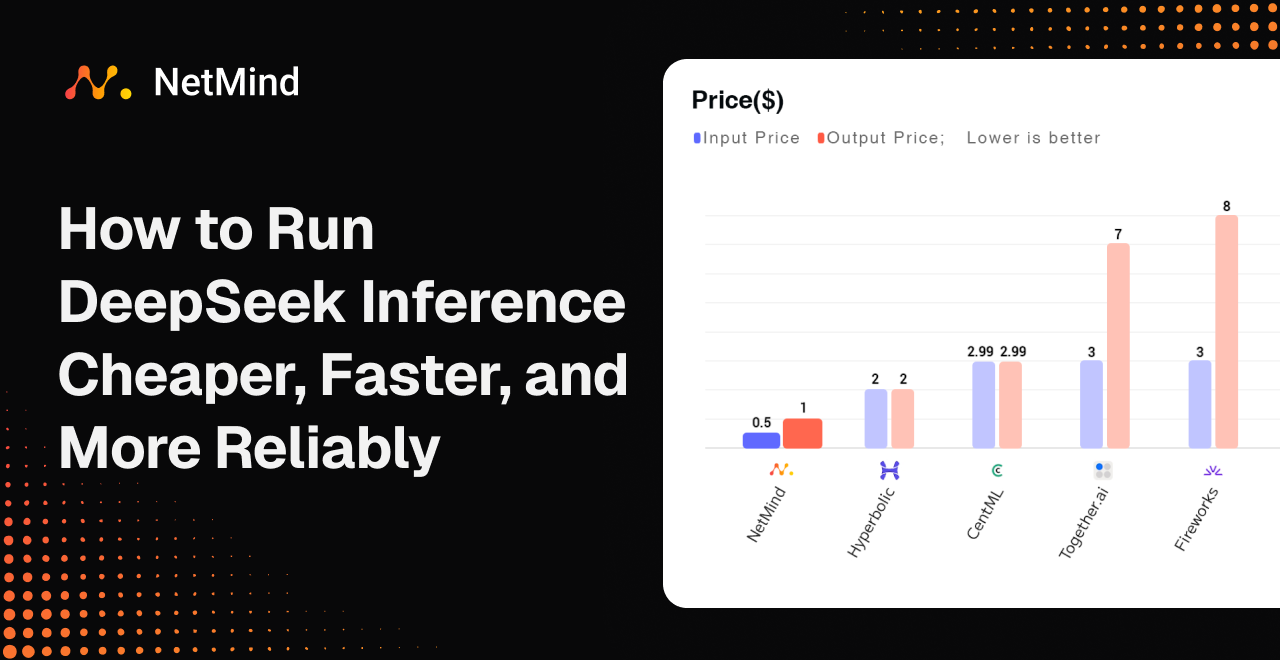
NetMind stands out as the most cost-effective and scalable DeepSeek inference provider, offering input/output pricing as low as $0.50/$1.00 and speeds of 51 tokens/sec—nearly matching Together.ai’s performance at a fraction of the cost.
-
The platform supports full model access (DeepSeek V3, R1, and latest versions), self-hosted infrastructure, and developer-friendly features like function calling, token-level rate limiting, and unified APIs - making it ideal for production-grade deployments.
In a world of rising AI costs, this guide is a blueprint for running smarter, leaner, and faster.
Read more at: blog.netmind.ai
2025-06-18